논문 링크 : https://arxiv.org/pdf/2008.06884.pdf
github 링크 : https://github.com/shengyuzhang/DeVLBert
Casual Inference에 대한 배경지식
1) Association vs Casuality
1> association : 상관관계
반드시 인과 관계를 의미하는 것이 아니라 관측되는 측정값을 통해 얻는다.
우리가 일반적으로 알고 있는 P(A|B)에 해당합니다.
2> casuality : 인과관계
실제로 두 확률 변수 event에 인과관계가 존재하는지를 파악합니다.
그래서 association과 달리 관측만으로는 알아낼 수 없습니다.
P(A|do(B))로 표기합니다.
2) Example

3) Confounder
위의 예시에서 아이스크림의 판매량과 모기 개체수가 인과관계가 아닙니다.
이 때, 온도처럼 그 사이에 껴서 상관 관계를 인과 관계로 착각하게 만드는 것들을 의미합니다.
4) 결론
그래서 우리는 이 논문을 통해 pretrain 과정에서 confounder의 영향력을 감소시켜서
pretrain 과정에서 model이 정확한 인과관계를 학습하도록 할 것입니다.
0. Abstract
pretraining data와 downstream data와의 차이
→ 해결 : likelihood-based (하지만 spurious correlation 문제가 발생)
→ 문제 : spurious correlation으로 인한 bias가 생긴다.
→ 이러한 문제를 해결하는 내용이다. (일단은 abstract는 이전에 읽어온 논문들과 비슷한 흐름이다.)
다만 이 논문에서 내가 얻고 싶은 답은 image와 text가 동시에 있을 때에는 어떻게 do-calculus를 적용하여 bias를 줄이는 지이다.
1. Introduction
0> transition from traditional association-based learning to causal intervention-based learning

1> 확률 차이 → bias

그림처럼 text와 object간의 확률도 연산이 가능하다.
어떻게 구할 수 있는가?
⇒ COCO, VG 등의 다량의 data를 통해 얻어낸 probability distribution을 github에 제공

2> 주요 contribution
[1] out-of-domain data와 downstream data의 distribution이 다르다는 문제를 조사
[2] DeVLBert 구조 자체를 제안 (BERT + causal intervention)
[3] downstream에서의 성능 향상
2. Related Works
2) Causality in Vision & Language
VC R-CNN은 visual domain에만 적용되었다.
3. Visio-Linguistic BERT
1) Bidirectional Transformer
0> 구조 : backbone structure는 BERT
1> text는 기존 BERT의 방식대로 representation을 만듭니다.
2> object = visual word
[1] object detector로 bounding boxes, 대응되는 object feature map 추출 (ex> Faster RCNN)
[2] 이를 BERT를 통해 새로운 representation을 만듭니다.
S : sentence의 약자
O : object의 약자
2) 2-stream Visio-Linguistic Modeling
one-stream : image와 text를 합쳐서 처리 (ex> UNITER)
two-stream : image와 text를 분리하여 처리 (ex> ViLBERT, DeVLBert)
two-stream은 text끼리, object끼리, 그리고 text와 object를 분리한 뒤 한 번에 처리하는 총 4가지 방법이 있을 것이다. 그리고 그 결과들을 합친다.
구조적인 차이 때문에 UNITER에도 적용 가능할까?
일단 가능할 것 같아 보입니다.
0> text만으로 query, key, value 구성할 수 있고, image만으로 query, key, value를 구성할 수 있다.
1> text를 query & image를 Key, Value
⇒ language-related information from visual feature를 얻는다.

2> image를 Query & text를 Key, Value
⇒ text에서 image에 관련된 feature를 얻는다.

4. Deconfounded Visio-Linguistic BERT
1) BERT in the causal view
1-1) 준비할 것들
1> 구성 및 식
Y : 하나의 output token의 representation
X : 그 외의 token들
z : confounder

2> classification에 맞게 식을 조정

x, z 모두 feature representation 상태를 말한다.
f_c : intervention의 classifcation head
3> f_c에 대한 modeling

⇒ 구현 방식은 VC R-CNN과 동일
4> y와 confounder z가 중복되는 경우
𝛼𝑦 (𝜍)를 0으로 설정한다.
1-2) BERT 단위에서 볼 것

논문에서느 총 4가지 구조를 제안해보고 모든 구조에 대해 실험을 진행하였습니다.
2) Intra- & Inter-modality Intervention
1> Vision deconfounding & Vision Confounder Set
→ VC R-CNN 처럼 진행한다.
2> Language deconfounding & Language Confounder Set
→ 명사를 confounder로 설정
(content word : 의미와 semantic value를 가지니까)
(명사의 역할이 object의 역할과 유사하다.)
→ nltk로 NN, NNS, NNP, NNPS를 추출한다.
5. Experiments
Design D 방식을 vision, language 모두 적용하는 것이 제일 성능이 높다.
1) 다른 model들과의 비교

task에 따라 다르지만 모두 DeVLBert에서 가장 높은 성능을 보이고 있습니다.
2) 4개 구조 중에서 어떤 것의 성능이 좋은지 비교
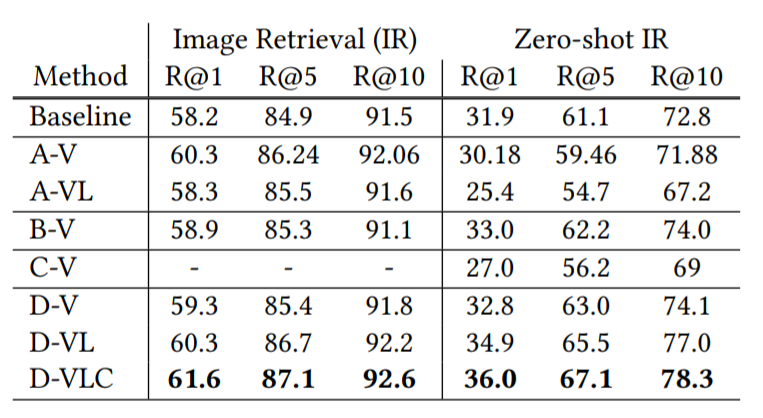
1> 구조에 대한 비교
압도적으로 D구조에서 좋은 성능을 발휘합니다.
2> D-V < D-VL < D-VLC
D-V : vision만 이용
D-VL : vision과 language만 각각 이용
D-VLC : D-VL + cross modality까지 이용
3) VC R-CNN과의 비교

task별로 성능 차이가 있지만
VC R-CNN처럼 causal inference를 간접 적용했을 때보다
DeVLBert처럼 causal inference를 직접 적용했을 때 성능이 높다.
