참고 강의 :https://bit.ly/3pFI7r5
5. Intoduction to NLG
1) Our Objective
컴퓨터가 인간이 만들어놓은 대량의 문서를 통해 정보를 얻고, (NLU)
얻어낸 정보를 사람이 이해할 수 있게 사람의 언어로 표현하는 것 (NLG)
2) Before Sequence-to-Sequence : text-to-numeric
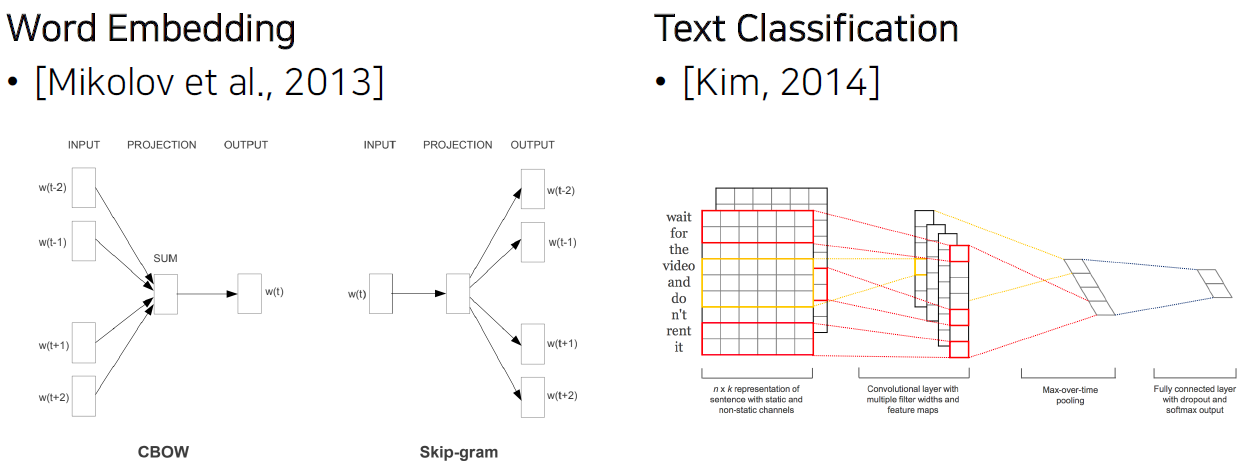
단순히 text를 숫자로 변환하는 것에 그쳤습니다.
3) After Sequence-to-Sequence with Attention : numeric-to-text

Seq2Seq의 Decoder라는 구조가 있어서 이제는 숫자를 text로 만드는 것도 가능해집니다.
4) Era of Attention
1> Transformer의 등장으로 인해 연구가 더 진전되었고
2> Pretrained Language Model 사용

1. Introduction
1) Language Model
1> LM이란? : 문장의 확률을 나타낸 모델
[1] 문장 자체의 출현 확률 예측
⇒ [2] 이전 단어들을 기반으로 다음 단어를 예측하기 위한 모델
2> 예시

'놓쳤다'가 나올 확률이 높다. (하지만 다른 단어도 위치할 확률이 작지만 있다.)
3> LM의 목표
우리의 머릿 속에는 단어와 단어 사이의 확률이 우리도 모르게 학습되어 있음
⇒ LM으로 많은 문장의 단어와 단어 사이의 출현 빈도를 학습
⇒ 우리가 사용하는 언어의 문장 분포를 정확하게 modeling 하는 것이 목표
(특정 분야의 문장 분포를 알고 싶은 경우 그 해당 분야에서 corpus를 수집하기도 합니다.)
2) LM의 한국어 적용
1> LM 적용의 어려움 : 한국어는 단어와 단어 사이의 확률 계산하기가 어렵다.
[1] 단어의 어순이 중요하지 않음
[2] 생략이 빈번하게 일어남
2> LM 적용의 어려움 대표적 사례 1: 확률이 퍼지는 현상
어떤 단어가 뒤에 올 확률이 비슷한 문제

3> LM 적용의 어려움 대표적 사례 2 : 접사로 인해 어휘가 너무 많다.
⇒ sparse한 문제 발생
⇒ 해결: 접사를 따로 분리해야한다.
3) LM의 적용

1> 예시 1 : Automatic Speech Recognition
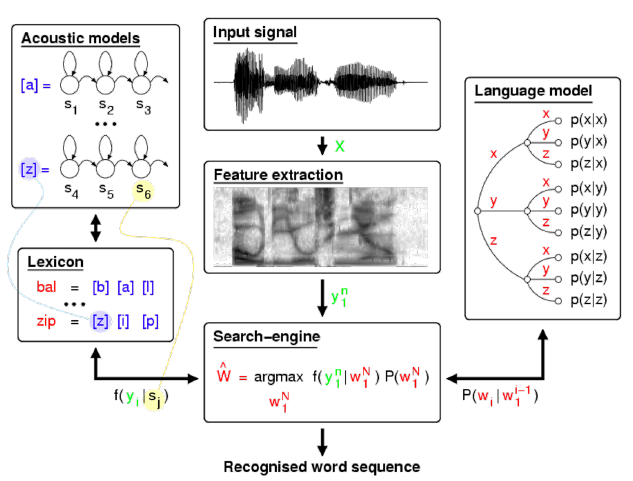

ASR에서도 음성 모델(AM) 뿐 아니라 언어 모델(LM)이 사용됨을 알 수 있습니다.
2. Language Modeling
1) Objective
1> 실제 존재하는 단어(문장)들의 분포에서 N개의 문장을 sampling
$$D = {x^{i}}^{N}_{i=1}, \ where \ x^{i} \sim P(x)$$
- P(x) : 실제 존재하는 단어(문장)들의 분포
- $x^{i}$ : P(x)에서 sampling한 단어(문장) (N개 sampling합니다.)
- D : N개 sampling한 단어들(문장들)
2> log likelihood를 최대로 만드는 $\hat{\theta}$를 찾는 것이 objective입니다.
$$\hat{\theta} = \underset{\theta\in\Theta}{\arg\max}\sum\limits_{i=1}^{N}logP(x^{i}_{1:n};\theta), \\where \ x_{1:n} = \{x_{1}, x_{2}, ..., x_{n}\}$$
3> loss
$$L(\theta) = -\sum\limits_{i=1}^{N}log(x^{i}_{1:n};\theta)$$
gradient descent로 parameter를 update할 수도 있고
NLL을 minimize하는 방식으로 parameter를 update할 수 있습니다.
2) Chain Rule : joint probability → conditional probability
: 단어들의 joint probability → 특정 sequence 다음에 단어가 올 conditional probability
1> 예시
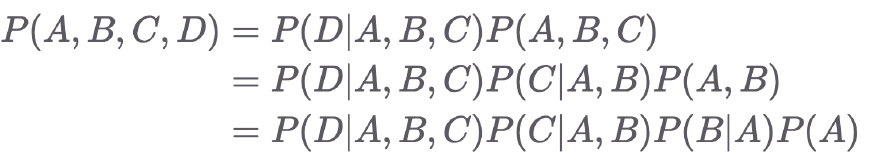

2> Chain Rule을 이용해서 log likelihood와 유사한 식을 유도할 수 있습니다.

3> objective를 새롭게 변형할 수 있습니다.

각 input별로 빨간 박스에 해당하는 식이 있는데 이들의 합이 최대가 되도록 만드는 $\hat{\theta}$를 찾으면 됩니다.
4) LM으로 할 수 있는 것
1> 여러개의 문장이 주어졌을 때, 어떤 것이 자연스러운지 고를 수 있습니다.
2> 단어들이 주어졌을 때, 다음 단어를 예측
cf> 수강한 클립명
1> Ch 01. Orientation - 04. 자연어 생성이란
2> Ch 02. Lauguage Modeling - 01. 들어가며
3> Ch 02. Lauguage Modeling - 02. 언어모델 수식
cf> 수강 인증샷
'NLG' 카테고리의 다른 글
| [자연어생성] 2-6강~2-8강 (0) | 2021.03.01 |
|---|---|
| [자연어생성] 2-3강~2-5강 (0) | 2021.02.26 |
| [자연어생성] 1-1강~1-3강 (0) | 2021.02.20 |


