5. Set
0) Set
[1] 원소간 중복을 허용하지 않는다. (no duplicate elements)
[2] 원소간 순서가 없다. (no ordering of elements)
1> Hierarchy of interfaces
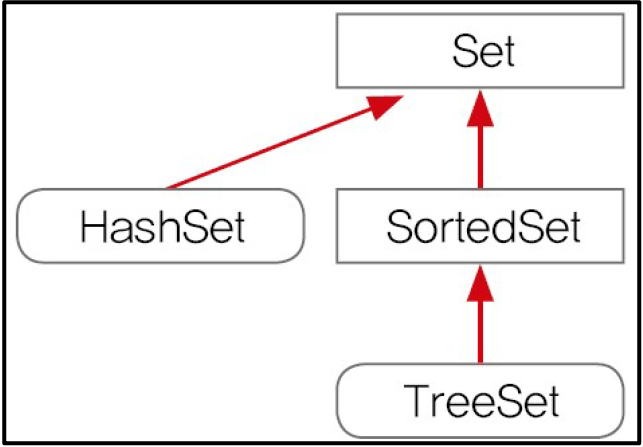
2> Interface Set<E>에 정의된 Method (Interface Collection<E>와 동일하다.)
1) HashSet
1> Method - Constructor
load factor : (float의 형태) load factor를 넘어서면, capacity를 2배로 확장시킨다.

2> 다른 Method

3> AbstractCollection의 method
- addAll, containsAll, retainAll, toArray(), toArray(T[] a), toString
4> AbstractSet의 method
- equals, hashCode, removeAll
5> <example 1>
set은 중복이 허용되지 않아서 "1234"가 출력됩니다.(하나씩만 저장됩니다.)
6> <example 2>1, 10, 5, 5, 20, 5, 8, 13이 뽑히면[1] list는 1, 10, 5, 5, 20, 5를 출력하고set은 1, 10, 5, 20, 8, 13을 출력[2] 해당 set으로 LinkedList를 만든다.
7> <example 3>
java 자체적으로 HashSet에는 설정된 order가 있습니다. 그래서 HashSet에 저장한 뒤에 element를 출력하면 일정한 패턴대로 element를 출력합니다.(이를 방지하기 위해 입력한 순서를 유지하는 set인 LinkedHashSet이 있습니다.)
8> <example 4>
복제 여부는 equals()나 hashCode()로 결정합니다.
이번 코드 내에는 Person class는 equals()와 hashCode()가 없어서 -> Set 내부에 중복된 것을 다르게 저장합니다.
(중복된 것을 같게 저장하려면 Person class에 equls()함수와 hashCode()를 오버라이딩 해야합니다.)
9> <example 5>
10> hashCode
equals()함수의 결과 true가 나오면 hashCode()의 결과가 같아야 합니다.
equals()함수의 결과 false 나오면 hashCode()의 결과가 달라야 합니다.
cf>
hashset은 hash로 data를 저장하고
treeset은 binary search tree로 data를 저장합니다.
2) TreeSet
0> binary search tree
[1] binary tree처럼 모든 node가 최대 2개의 child node를 가집니다.
[2] 더 나아가 왼쪽 child에는 더 작은 value를, 오른쪽 child에는 더 큰 value를 저장한다. (정렬된다.)
1> TreeSet
[1] Binary Search Tree로 data를 저장
[2] 중복이 없다.
[2] sort, search, range search하는데 좋은 성능을 보입니다.
2> Method - Constructor

3> Method


SortedSet<E> headSet(E toElement) : toElement보다 작은 것들의 set을 return
tailSet(E fromElement, boolean inclusive) : fromElement보다 큰 것들의 set을 return
subset(E fromElement, E toElement) : fromElement보다 크고 toElement보다 작은 set을 return
4> <example 1>
treeset은 정렬이 된 채로 저장되기 때문에 따로 sort가 필요하지 않습니다.
5> <example 2>
6> <example 3>
'JAVA' 카테고리의 다른 글
| [Java] 7-1강 - 네트워킹 with 자바 1(network 기본 개념, InetAddress, URL) (0) | 2020.12.05 |
|---|---|
| [Java] 6-4강 - Collection Framework 4 (Map) (0) | 2020.12.05 |
| [Java] 6-2강 - Collection Framework 2 (Iterator, Arrays, Comparable) (0) | 2020.12.04 |
| [Java] 6-1강 - Collection Framework 1 (List - ArrayList, Vector, LinkedList, Stack & Queue) (0) | 2020.12.03 |
| [Java] 6-0강 - Collection Framework (0) | 2020.12.03 |



