SAS에서 기술 통계를 위한 주요 절차 (기술 통계를 나타내는 procedure)
=> MEANS, UNIVARIATE, FREQ, GCHART, GPLOT, CORR
1. MEANS
0) 소개
일변량 자료의 평균, 표준편차, 최대, 최소 등의 정보를 제공
(UNIVARIATE처럼 여러가지 기술 통계량이 나온다.)
1) 문법
1> 기본 문법
- PROC MEANS <option-list> ;
2> 그 외
- VAR variables : 분석하고자 하는 변수 지정 (지정하지 않으면 모든 변수에 대한 MEANS를 출력해서 결과가 길어진다.)
- BY variables : BY 변수의 수준별로 결과 출력 (성별 변수이면 M에 대해 따로, F에 대해 따로 출력) (SORT되어 있어야함)
- OUTPUT OUT=SAS-data-set keywords : 저장 장소 지정 (사용 가능한 keyword는 조금 뒤에 언급하겠습니다.)
3> option-list
- DATA = SAS-dataset : 분석하고자 하는 데이터 세트 명시
- NOPRINT : data-set만 구하고 결과를 출력시키지 않음 (이게 없으면 원래 자동 출력)
cf> UNIVARIATE와의 차이점
UNIVARIATE는 많은 통계량이 자세하게 나오고
MEANS는 간단하게 나온다.
2) PROC MEANS에서 디폴트로 출력되는 통계량들
N (자료의 수) Mean (평균) Std Dev (표준편차) Minimum (최소값) Maximum (최대값)
3) 예제
1> 예시 1
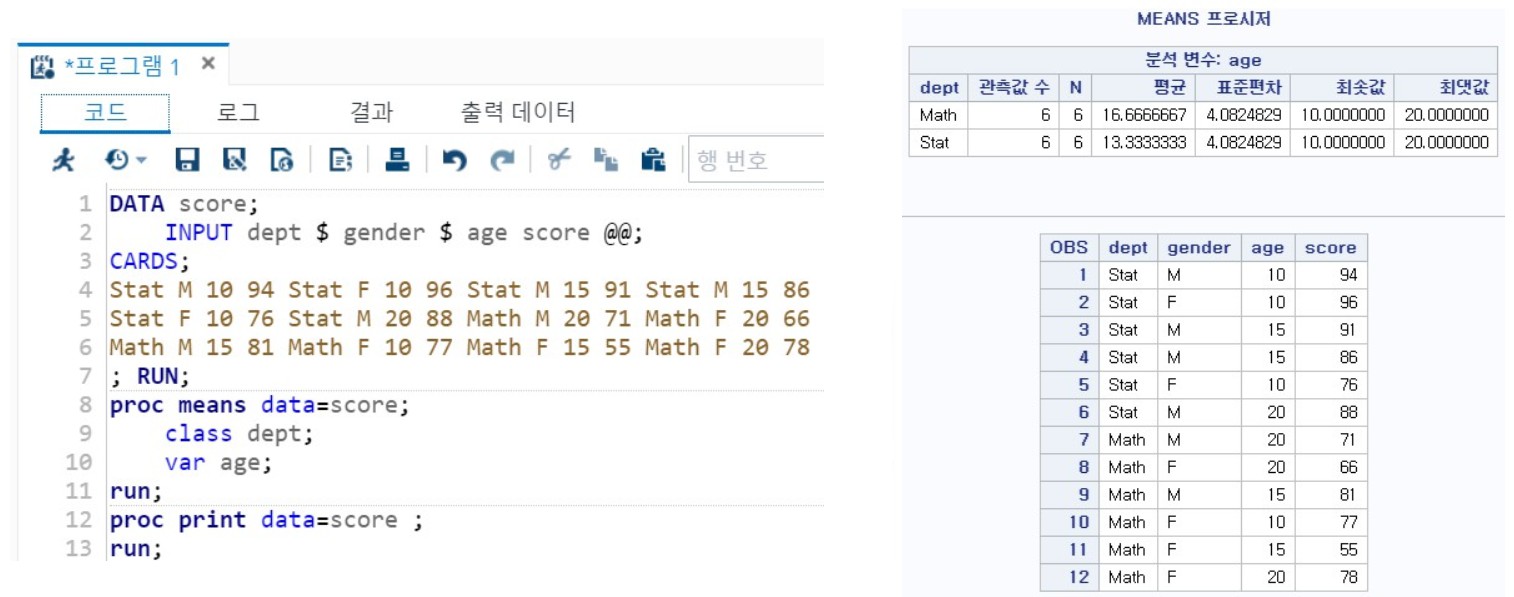
- MEANS 자체가 자동으로 출력을 하니 PRINT 문과 함께 2개의 결과를 출력한다.
- CLASS : BY와 유사한데 SORT없이 사용할 수 있다.
2> 예시 2 (output관련)

- MAXDEC : 소수점 몇째짜리까지 표현할 지
- max mean min cv : 나타내고 싶은 통계량 지정 (default : N, Mean, Std Dev, Minimum, Maximum)
- OUTPUT OUT=scoreout : scoreout이라는 dataset 생성
- mean (age score)=m_age m_score : 기존 age와 score의 평균 이름을 m_age, m_score로 변경
- score는 MEANS에서 출력하고(자동), scoreout은 PRINT에서 출력되었다.
- PRINT 결과 우리가 모르는 변수 '_TYPE_', '_FREQ_'가 나왔다. 이를 자동 생성 변수라고 한다.
- _TYPE_ : class를 dept와 gender로 나누었는데 [0은 아무것도 분류하지 않은 것] [1은 첫 번째 변수 gender로 나눈 것] [2는 dept로 나눈 것] [3부터는 교차해서 같이 구분한 것]
- _FREQ_ : 그래서 _TYPE_에 따라 각각 몇 개의 항목이 있는가? (빈도를 의미)
cf> output의 keyword

2. UNIVARIATE
0) 소개
1>일변량 자료에서 다음의 정보를 제공
- 자료의 평균, 표준편차, 분산 등
- 중앙값과 사분위수, 최대, 최소
- 극단 값들 (outlier)
- 분포의 형태를 파악할 수 있는 여러 가지 그림
1) 문법
1> 기본 문법
PROC UNIVARIATE <option-list>:
2> 그 외
VAR variables : 분석하고자 하는 변수 지정
BY variables : BY 변수의 수준별로 결과 출력 (BY 대신에 정렬이 필요 없는 CLASS를 써도 된다.)
OUTPUT OUT=SAS-data-set keywords : 저장 장소 지정
3> option-list
- DATA = SAS-data-set : 분석하고자 하는 데이터 세트 명시
- PLOT : 줄기-잎 그림, 상자그림, 정규분포 분위수대조도 등을 그려준다 (MEANS와 달리 그림을 그릴 수 있다.)
- FREQ : 도수분포표 작성
- NORMAL : 정규성 검정을 위한 검정 통계량 값 계산 (정규 분포를 따르면 어떻게 되는지, 정규성 검정)
- HISTOGRAM : 히스토그램 그리기 (기억하기 히스토그램은 PROC에 있는 게 아니라 UNIVARIATE 내부 옵션에 있다.)
2) 예제
1> 예제 1 (결과 부분은 UNIVARIATE 부분을 제외하고 histogram만 캡쳐했습니다.)

- 'class gender'를 해야 위 그림처럼 한 그림 안에 2개의 histogram을 그린다.
- by는 한 과정을 끝내고서 순차적으로 진행하기 때문에 histogram을 각각 그린다.
- slash('/')의 의미 : slach('/') 뒤에 오는 건 해당 명령어의 옵션들을 의미한다.
- histogram의 option들
- outhistogram=변수 : histogram을 해당 변수에 저장 원래 밖으로 꺼내갈 때 out이나 output이란 용어 사용
- cfill=color : histogram 내부를 채울 색 설정
- vaxis=숫자1 to 숫자2 by 숫자3 : vaxis는 y축을 의미 ('숫자1'부터 '숫자2'까지 '숫자3' 단위로)
- midpoints=숫자1 to 숫자2 by 숫자3 : x축을 의미 (숫자 형식은 vaxis와 동일)
- nrow=2 ncol=1 : 2개의 행과 1개의 열로 2개의 histogram을 그린다. (총 개수를 잘 만들어야한다.)
2> 예제 2
위에서 만든 outhisto를 PRINT로 출력한다. (histogram의 결과를 출력)

- label : 별칭 만드는 명령어인데 왜 사용하는가? 안 쓰면 원래 변수가 들어간다.

3> 예제 3
UNIVARIATE에서 특정 변수를 가지고 무언가 만들고 싶다.
=> VAR과 OUTPUT OUT을 이용한다.

(결과의 윗 부분은 UNIVARIATE를 출력하고 맨 밑에 univ_out이라는 OUTPUT을 따로 PRINT했다.)
- var super age : super와 age 변수를 이용하겠다. (추후 output에서 이용할 예정
- output out = univ_out : univ_out이라는 dataset을 새로 만든다.
- mean=s_mean a_mean std=s_std a_std : super와 age에 대한 평균과 표준편차를 s_mean a_mean s_std a_std로 설정
(super가 첫 번째 변수니까 첫 번째에 있는 s_mean이 super에 대한 평균이다.) (즉, 순서대로 들어간다.)
- pctlpts=33.3 66.6 : pctipts는 몇 퍼센트에 있는 data의 값을 의미 (그래서 33.3%, 66.6%에 해당하는 값을 의미)
(pctlpts : percent line points)
- pctlpre=s_p a_p : 접두어를 어떻게 붙일 지 ('s_p33.3' 와 같은 형식으로 column 설정이 된다.) (접미어는 pctlname)
- 위와 같이 univ_out이라는 dataset을 만든 뒤 PRINT로 출력한다.
4> 예제 4
위의 방법과 달리 그림을 손 쉽게 나오게 하는 명령어가 있다. (PLOT)

- PLOT을 썼더니 UNIVARIATE까지는 유사하나 중간 중간에 여러 그림이 등장한다.
- histogram, 상자-수염 그림, 정규 확률도가 PLOT을 이용해 출력할 수 있다.
- 상자-수염을 보니 여자는 평균이 중위수보다 크다
중위수(중간값은) 최빈값에 영향을 받는다. => 중간값은 최빈값에 가깝다.(평균은 최빈값과 멀다.)
=> 아래 두 그림 중 오른쪽 그림이다 => 오른쪽 꼬리가 길다.

- 여자의 정규도(정규성 검정)를 보면 직선에 가깝다 => 정규 분포에 가깝다
cf> 상자수형
상위 1/4, 하위 1/4
중간의 다이아몬드가 평균을 의미
'SAS' 카테고리의 다른 글
| 6-3강 - 자료의 정리 및 요약 3 (FREQ) (0) | 2020.04.26 |
|---|---|
| 6-2강 - 자료의 정리 및 요약 2 (BOXPLOT, SUMMARY) (0) | 2020.04.26 |
| 5-2강 - SAS 기본 procedure 2 (PRINT, RANK) (0) | 2020.04.19 |
| 5-1강 - SAS 기본 procedure 1 (SORT, GCHART) (0) | 2020.04.16 |
| [통계 개념] 4강 - 여러가지 확률 분포 (0) | 2020.04.16 |



